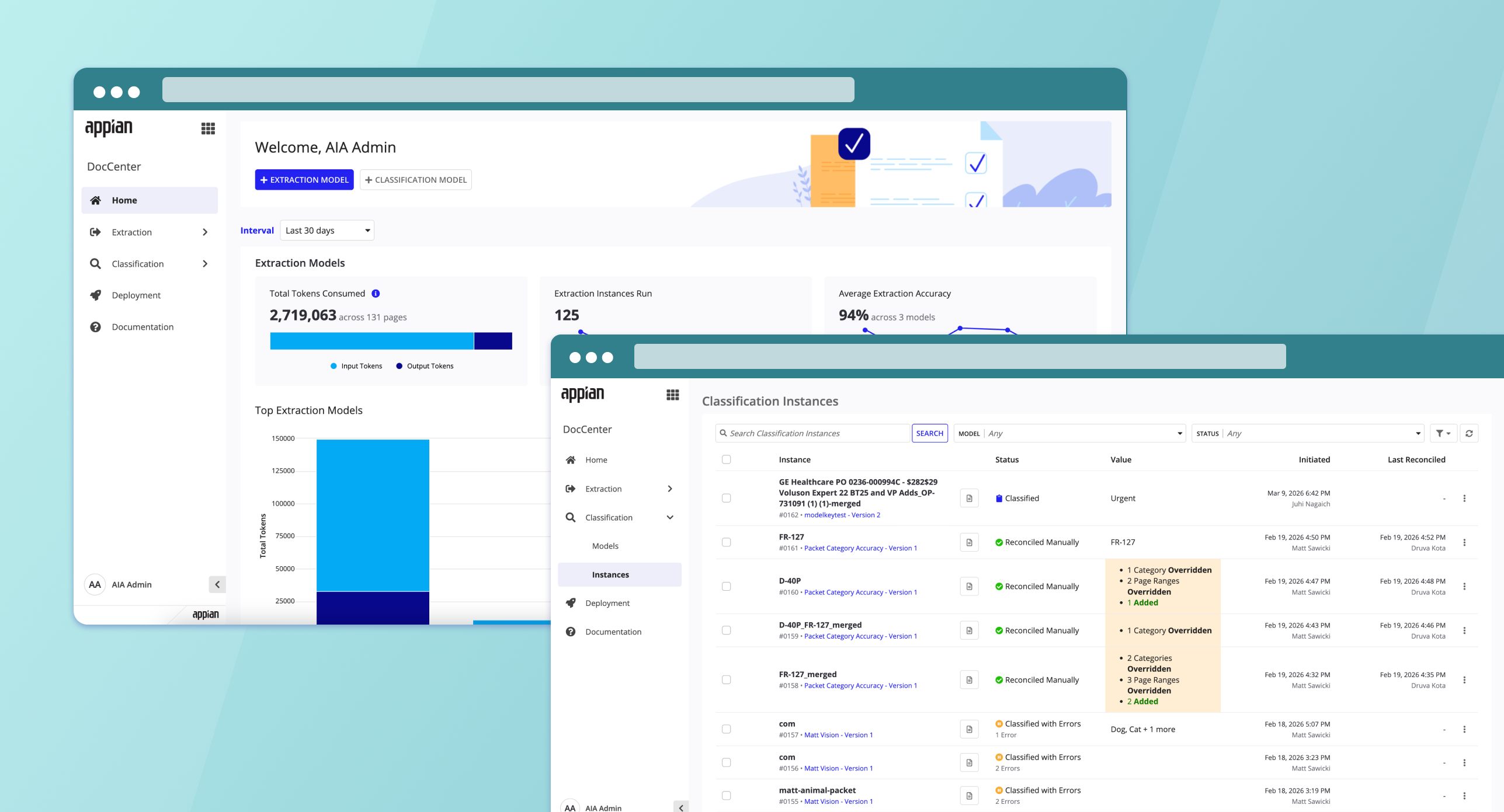
DocCenter
I co-lead UX for Appian's intelligent document processing platform -- making it possible for users of all technical backgrounds to build, test, and refine AI models for classifying and extracting data from complex documents.
Role
UX Design Co-Lead
Timeline
Sept 2025 - Present
Team
Product, Eng, AI
Scope
End-to-end Design
Product Overview
DocCenter is Appian's platform for intelligent document processing. Think of it as the tool that lets organizations teach AI how to read their documents -- classifying them by type and pulling out the data that matters. As one of the two UX leads, my job is making that process feel manageable for everyone, not just ML engineers.
Classification
Build AI models that automatically classify documents by type, with built-in testing to ensure accuracy.
Extraction
Create and configure AI models to extract data from complex documents with varied layouts.
Monitoring
Track accuracy of classification and extraction models across development, testing, and production.
Testing & Versioning
Rapidly iterate on models by testing directly in the app, reconciling results, and viewing performance metrics.
Key Features
Detailed walkthroughs of the design challenges I tackled and the decisions behind each solution.
Context
In many industries -- insurance, mortgage, healthcare -- documents don't arrive one at a time. They come as bundled PDF packets: a single file containing multiple documents like insurance forms, purchase orders, or medical records stapled together.
Before packet splitting, users had to manually break apart these multi-document PDFs before uploading them for classification. For teams processing hundreds or thousands of packets a day, this was a massive bottleneck. The goal was to let the classification model handle this automatically -- identify where one document ends and another begins, split them, and route each one for downstream extraction.
User Research
I interviewed solutions architects working with two active customer engagements -- a healthcare equipment manufacturer (3-15 docs per case) and a lending institution (50-100 page loan packets with 15-30 document types). Both had built fragile multi-step workarounds to compensate for DocCenter's single-document limitation.
Pain Points
Multi-step workarounds
Both teams built 3-step pipelines (extract page ranges, split PDF, then classify) as a workaround -- adding fragile steps and consuming excessive tokens.
Boundary detection failures
The extraction step struggled with visually similar documents, merging them into a single page range instead of recognizing where one document ended and the next began.
Custom wrappers required
Teams had to build custom orchestration layers around DocCenter to handle the one-case-to-many-documents relationship it didn't natively support.
False positives without catch-all
Without an "Other" category, the model force-fit unknown documents into existing categories, creating classification errors that were hard to trace.
Key Insights
Splitting belongs in classification. Moving packet splitting into the classification step would eliminate an entire processing stage. Both architects independently asked for this as a simple toggle in model config.
Accuracy over speed. Customers consistently prioritize classification accuracy over processing speed -- they'd rather break tasks into smaller, targeted prompts even if it takes longer.
Two levels of "multiples." DocCenter needs to handle both one case containing many documents and one file containing multiple document types within it.
Design Direction
Build packet splitting directly into the classification model configuration as a simple opt-in -- not a separate tool or multi-step pipeline. Include an "Other" catch-all category by default, and design the reconciliation flow to let users verify and correct AI-detected boundaries before data flows downstream.
How It Works
Packet splitting is enabled during classification model configuration. The workflow is designed to be low-friction -- just one toggle and a familiar reconciliation flow:
Identify & Separate
Automatically detect where one document ends and the next begins within a single upload (e.g., insurance bundles or bulk purchase orders).
Updated Reconciliation Interface
Use the updated UI to verify split points and ensure 100% accuracy before the data hits your core systems.
Early User Flow
Before jumping into UI, I mapped out the core user flow and key design questions -- how the AI should split documents (by logical boundaries vs. page numbers), whether to offer pre-trained classification out of the box or let users teach custom document types, and the tradeoffs between accuracy and upfront effort.
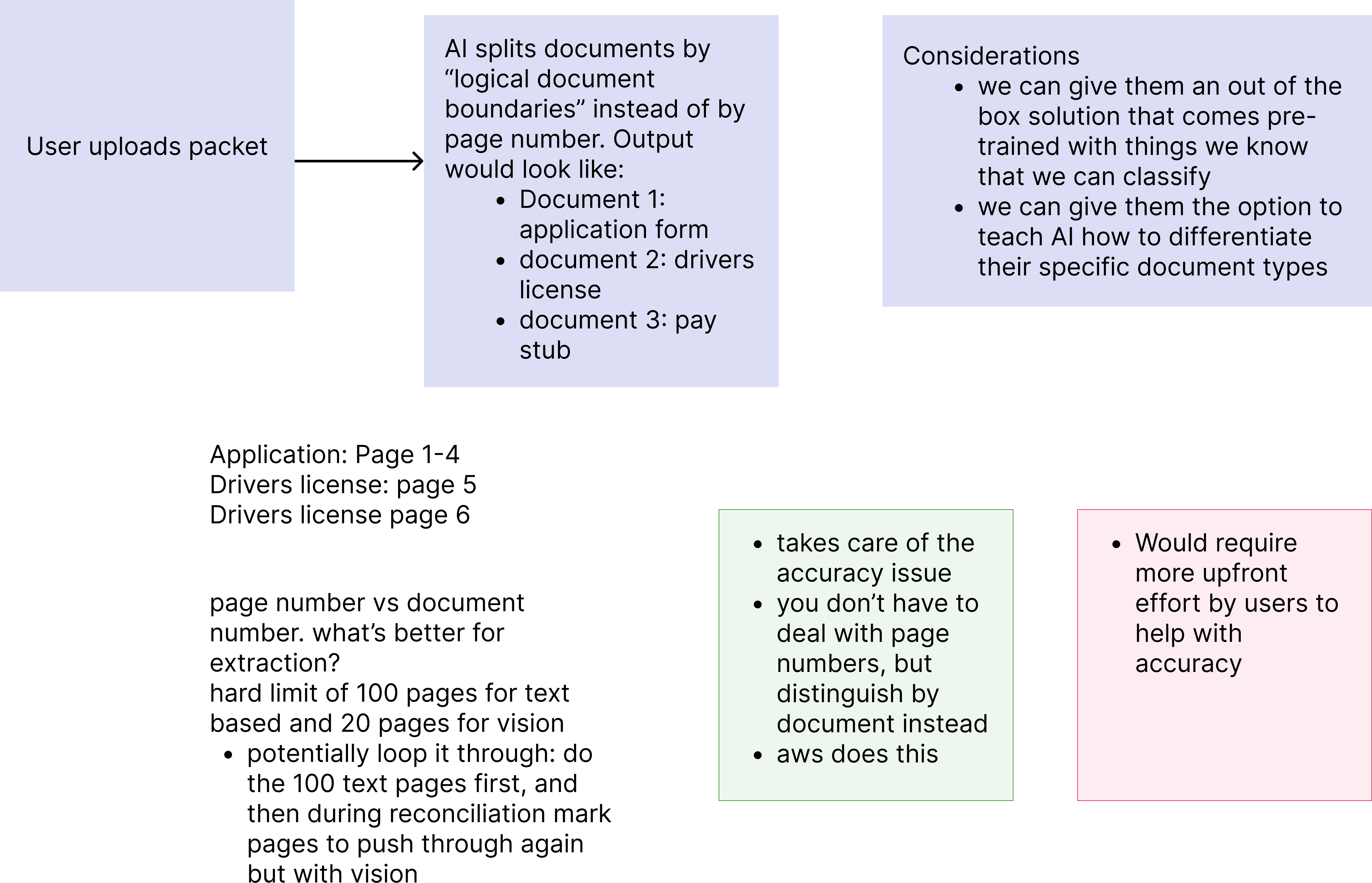
Early user flow -- exploring how the AI identifies document boundaries, output structure, page limits (100 text / 20 vision), and the pros and cons of document-based vs. page-based splitting.
Competitive Research
I researched how the major cloud platforms handle multi-document packet splitting to identify gaps and opportunities for DocCenter's approach.
Google Cloud Document AI
Uses a two-phase approach: developers first train a Custom Splitter model by manually labeling page ranges per document type in the Document AI Workbench, then deploy it as an API. The AI learns visual and textual features of each document type, so page order doesn't matter.
AWS Bedrock Data Automation (Modern Flow)
The newer, recommended AWS path. Developers create "Blueprints" (schemas) for each document type, configure a project with splitting enabled, and deploy as an API. Bedrock handles split, classify, and extract in a single pass -- closer to Google's single-product experience.
AWS Textract + Comprehend (Classic Flow)
The legacy "build-it-yourself" approach: train a Comprehend classifier, burst PDFs into single pages via Lambda, classify each page individually, write custom grouping logic, then route to Textract for extraction. Full control but extremely complex orchestration.
Also Evaluated
Blue Prism, Microsoft Azure Document Intelligence (custom classification models), and Twyzer were also reviewed as part of this competitive landscape.
Key Takeaway for DocCenter
Every competitor requires significant developer involvement to set up packet splitting -- from manual labeling (Google) to multi-service orchestration (AWS Classic). DocCenter's approach of a single toggle at model creation with a familiar reconciliation review flow is a major differentiator for low-code users.
Mid-Fi Mockups
With the user flow validated, I moved into mid-fidelity wireframes to define the UI structure across two key surfaces: model creation (where packet splitting is configured) and reconciliation (where users verify split results).
Create Classification Model
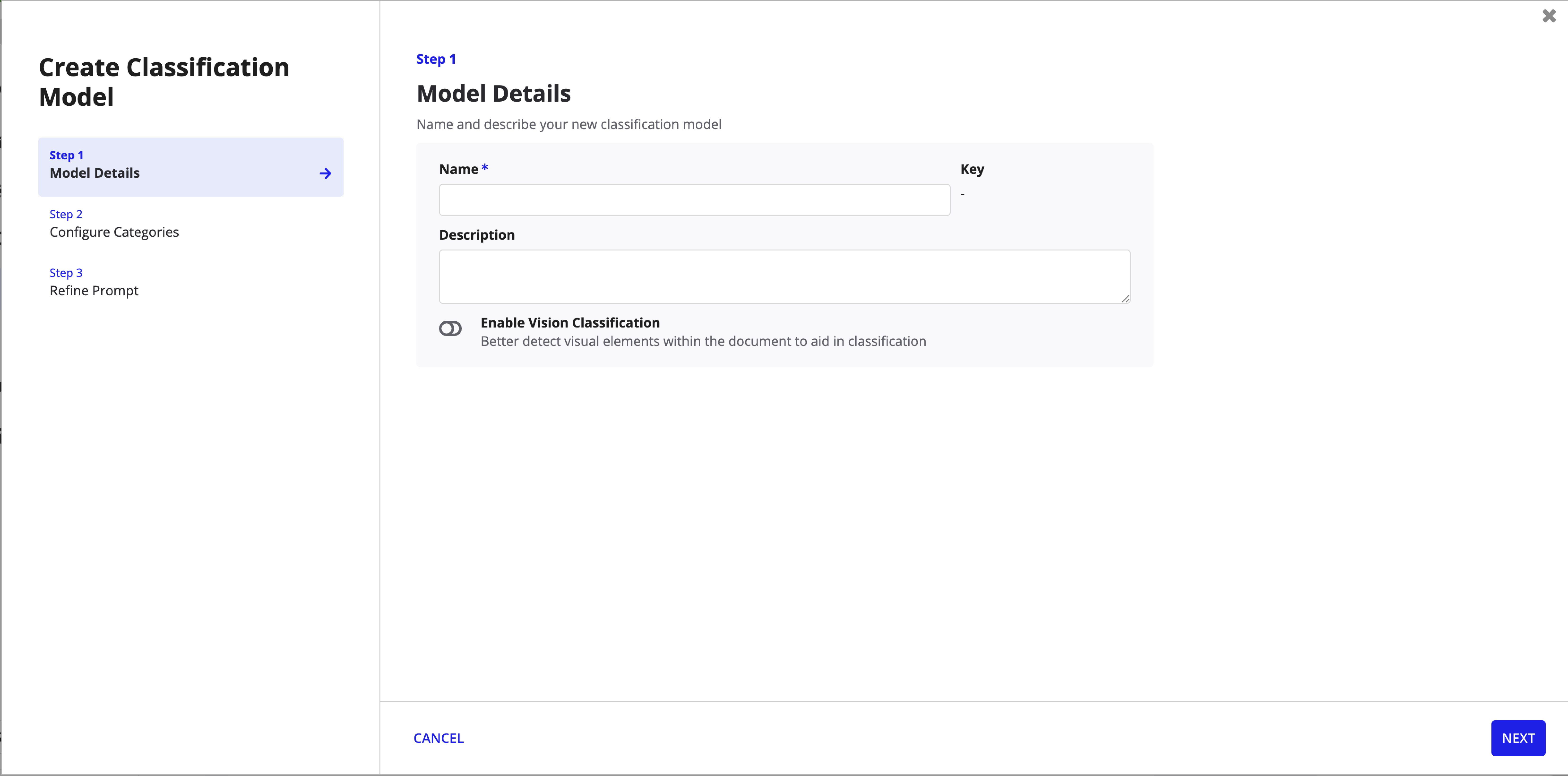
Step 1: Model Details -- name, description, and vision toggle.
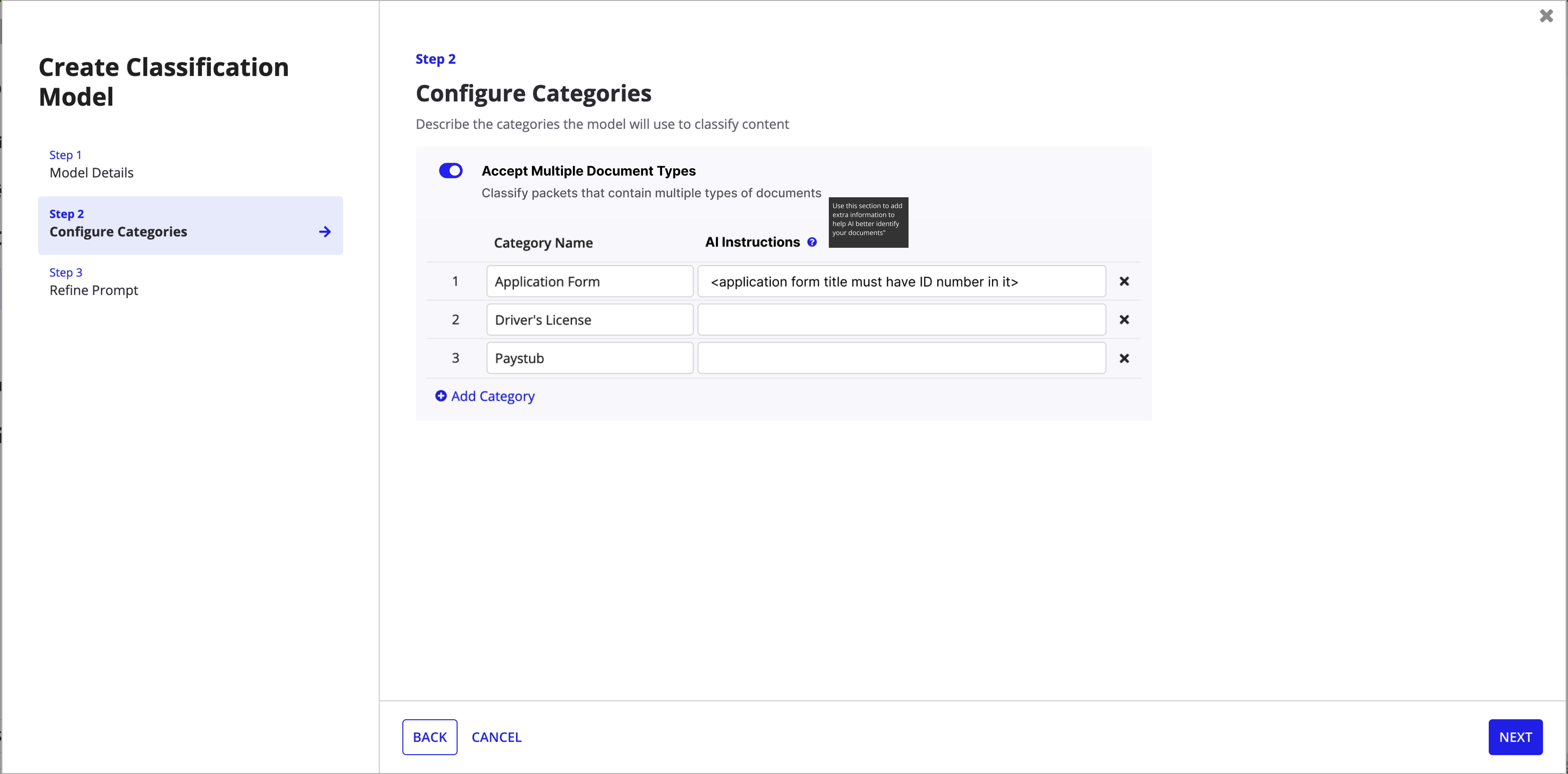
Step 2: Configure Categories -- the "Accept Multiple Document Types" toggle enables packet splitting.
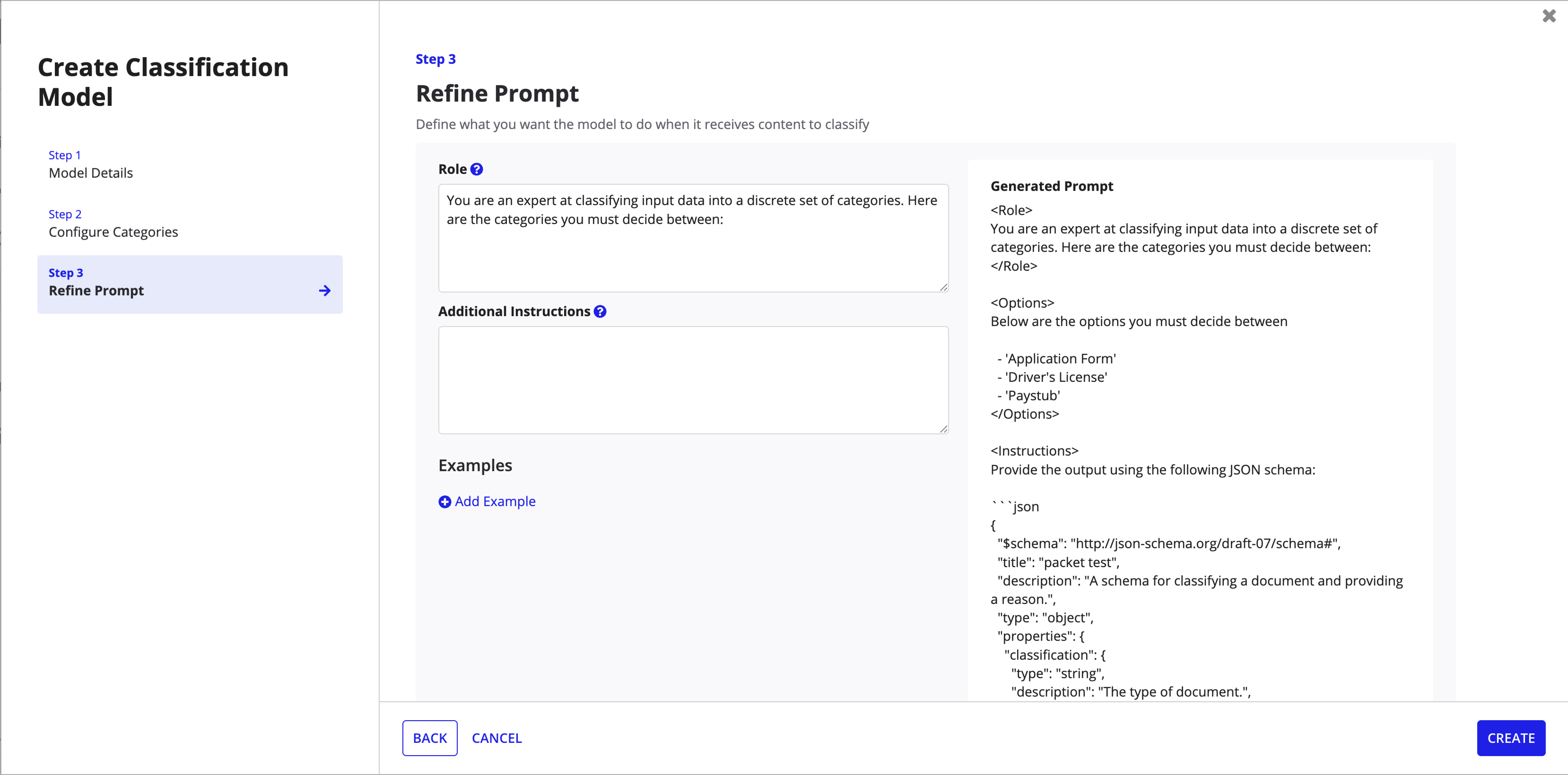
Step 3: Refine Prompt -- role definition, instructions, and generated prompt preview.
Reconciliation Flow
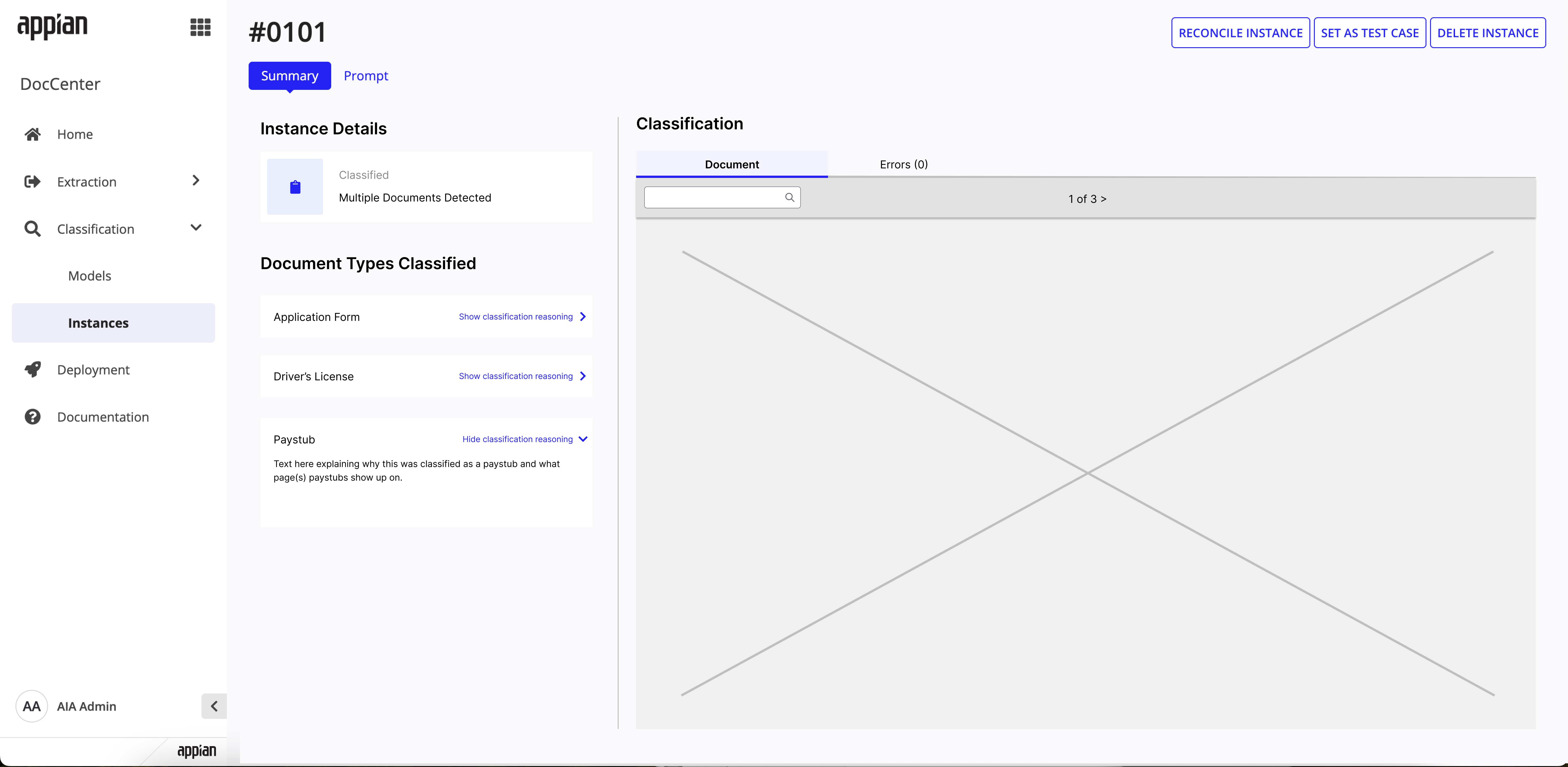
Instance summary -- shows "Multiple Documents Detected" with per-type classification reasoning.
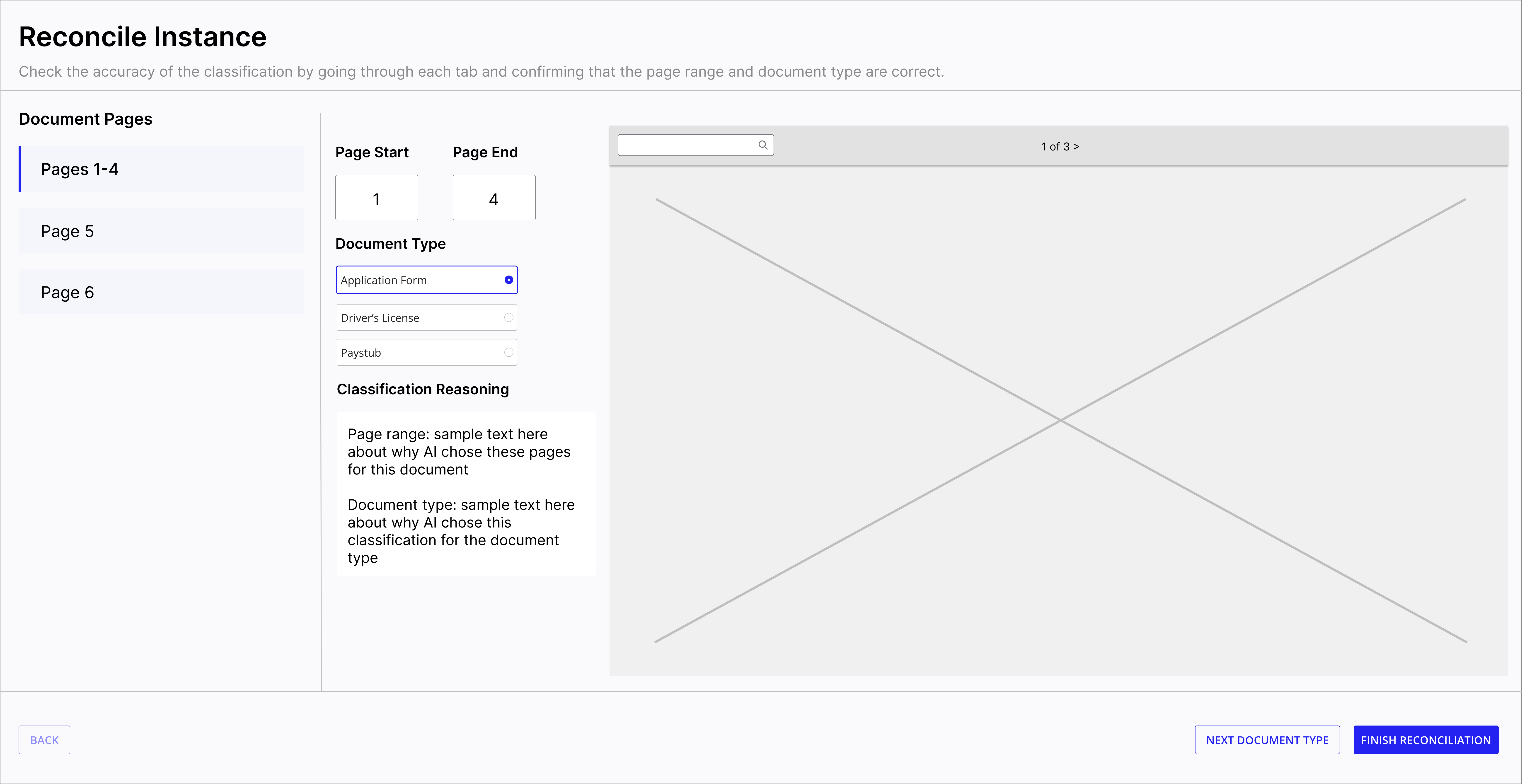
Reconcile view -- Pages 1-4 classified as Application Form with editable page ranges.
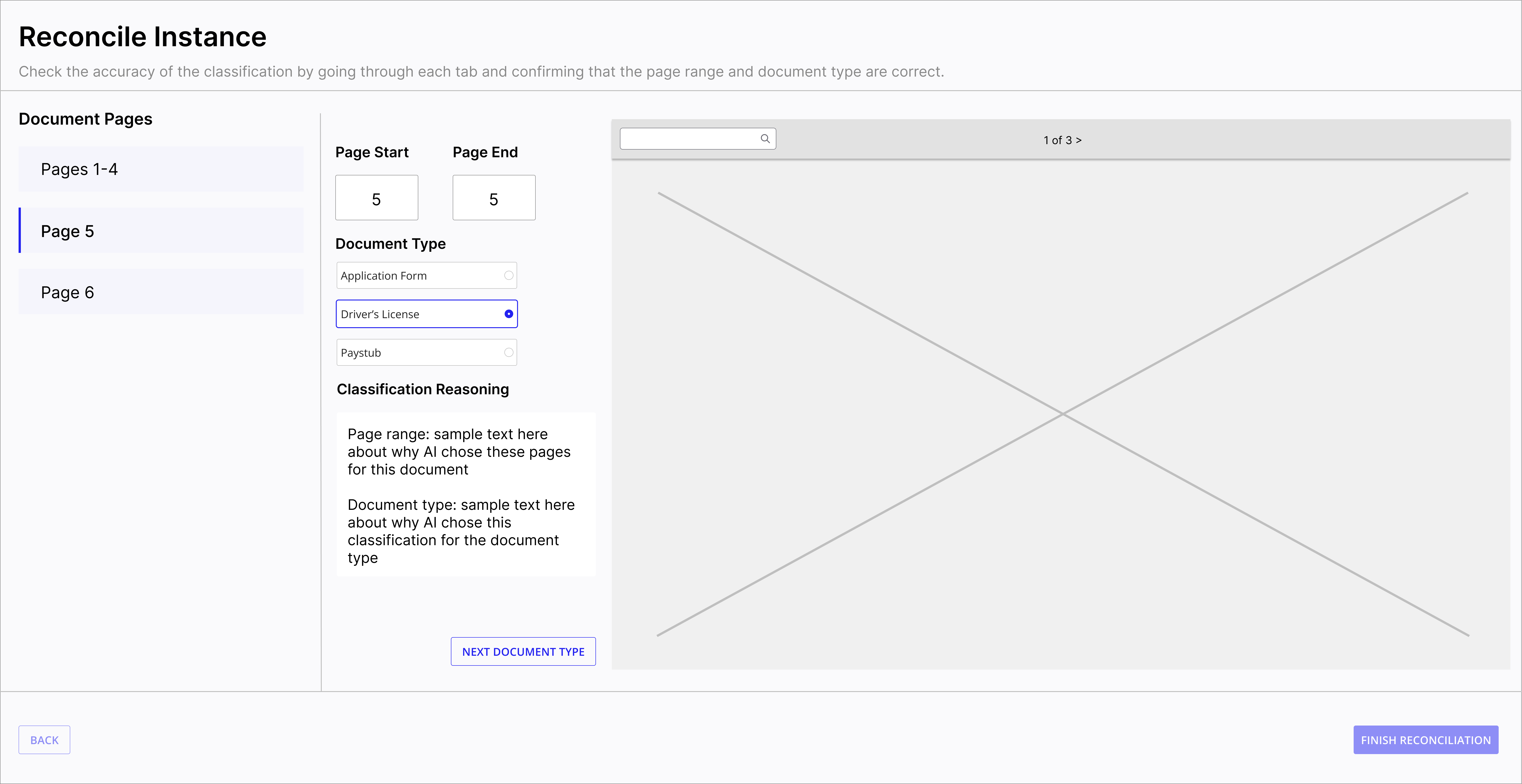
Reconcile view -- Page 5 classified as Driver's License, navigating between split documents.
Key Design Decisions
Opt-in at model creation
Packet splitting is a toggle, not a default. Not every classification model deals with bundled PDFs, so I kept it opt-in to avoid adding complexity for users who don't need it.
Reuse the reconciliation pattern
Rather than introducing an entirely new review flow, I extended the existing reconciliation interface to show split results. Users already know how reconciliation works -- this just adds page range verification to the familiar pattern.
Seamless extraction handoff
Once packets are split and classified, individual documents are automatically routed for extraction. The design ensures users don't need to re-upload or manually connect split outputs to extraction models.
Final Solution
The shipped feature spans model configuration, version management, instance tracking, and a fully redesigned reconciliation flow for multi-document packets.
Model Configuration
Packet splitting is enabled in Step 2 of model creation with a clear choice between single-document classification and multi-document splitting. The update modal exposes the same toggle for existing models.
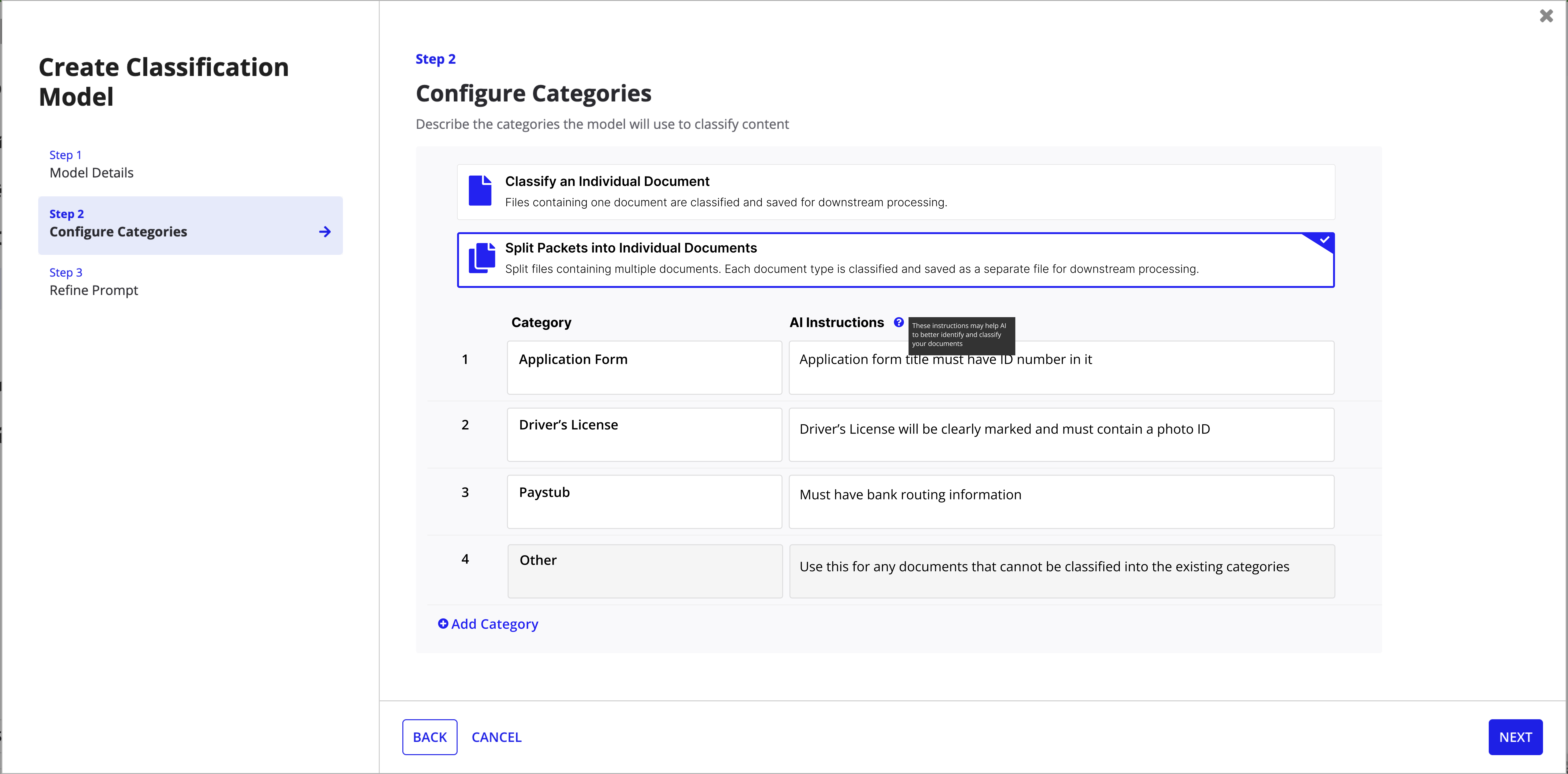
Create model -- Step 2 with explicit split vs. single-document choice and an "Other" catch-all category.
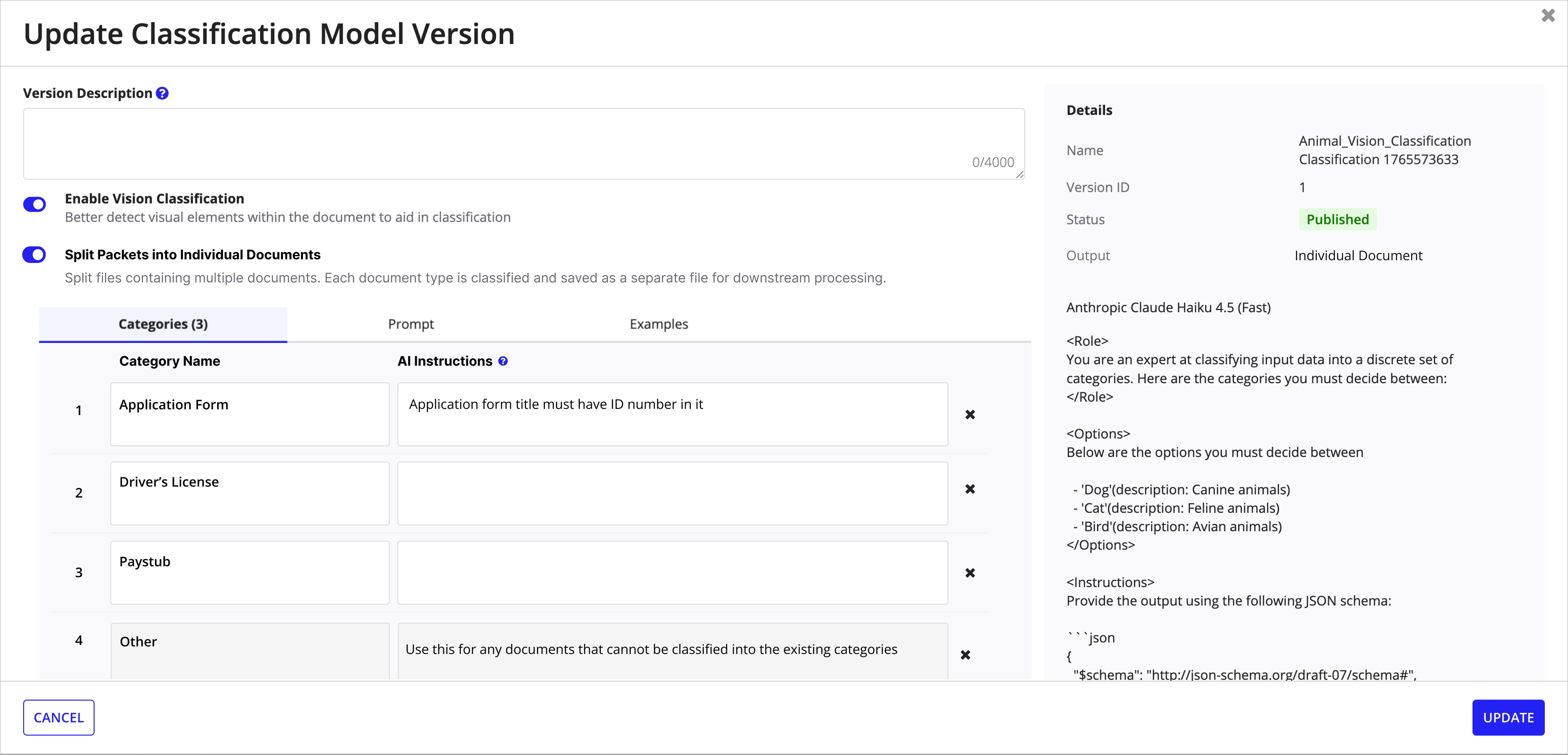
Update model version -- toggle splitting on/off with version details and prompt preview.
Model Management
Models list and version history surfaces make packet splitting visible at a glance with tags and the "Multiple Outputs" column.
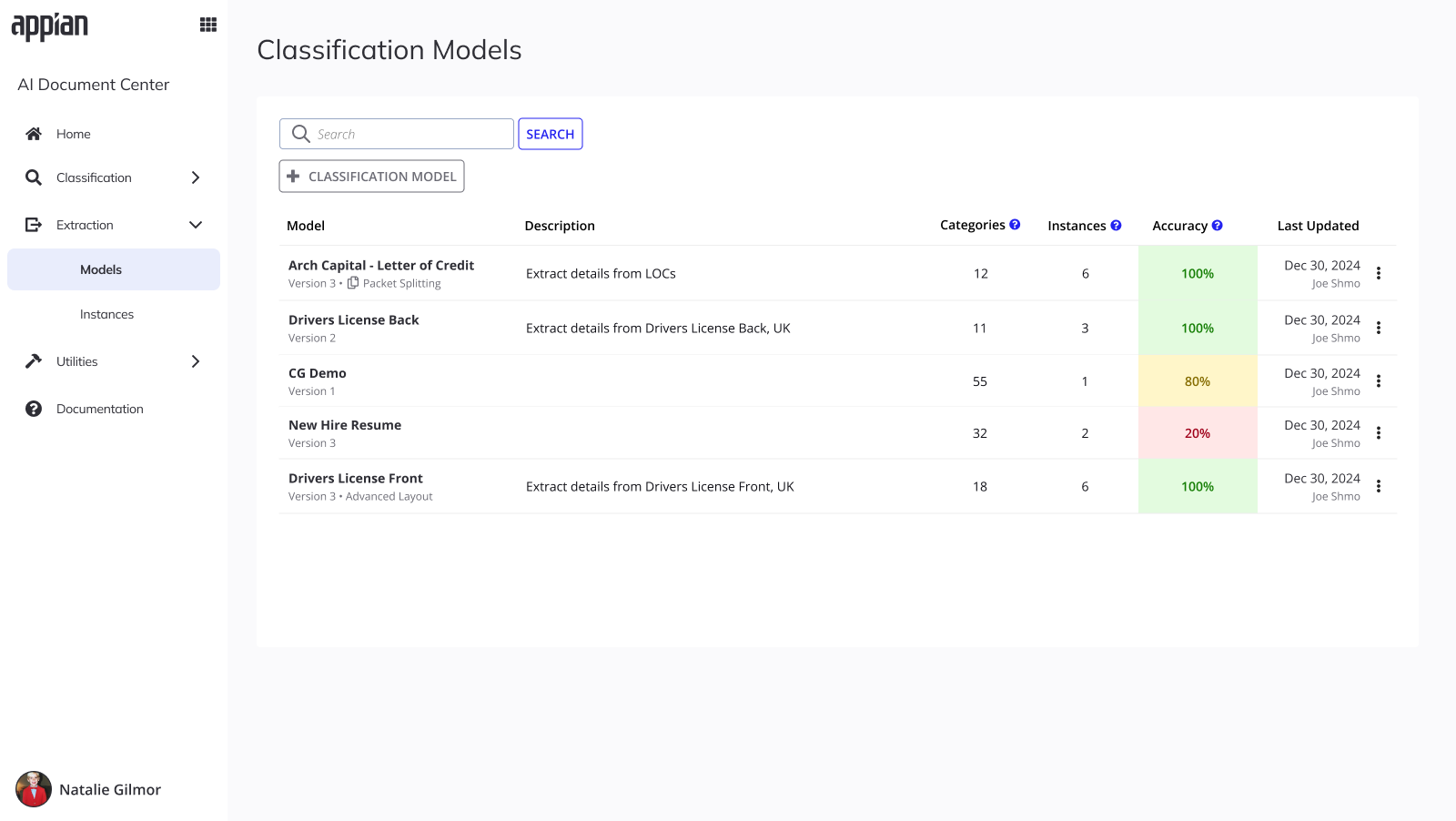
Models list -- Packet Splitting tag visible at a glance with color-coded accuracy.
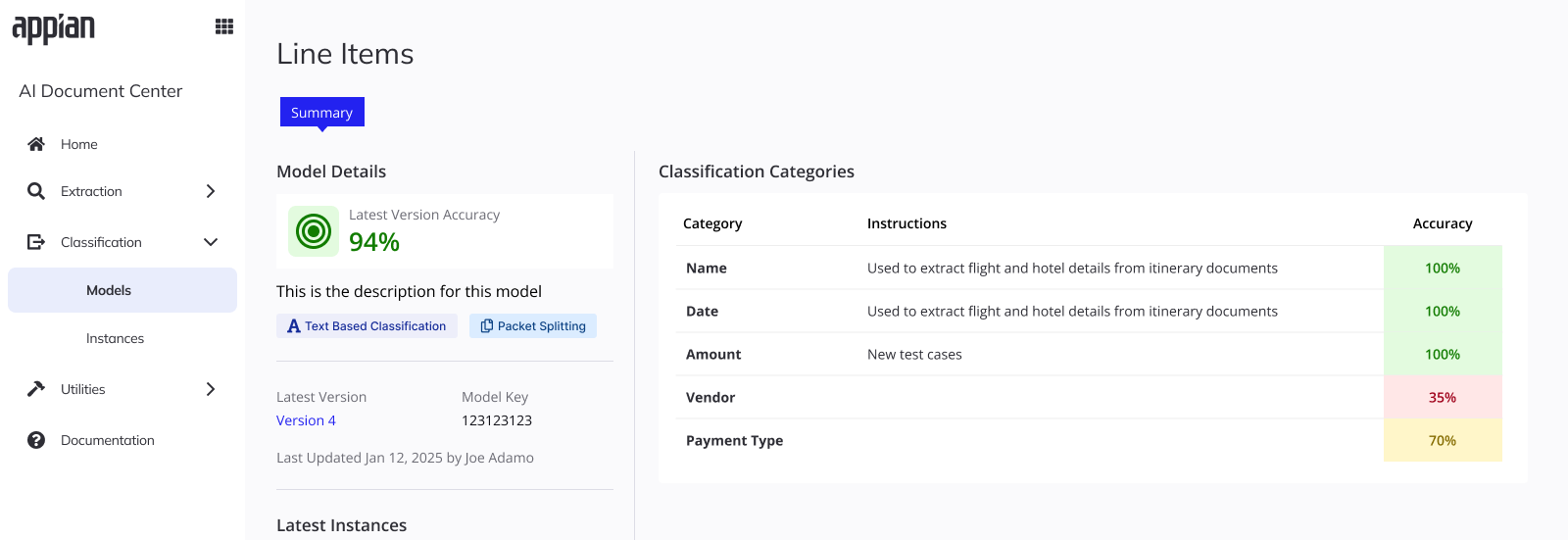
Model summary -- accuracy breakdown per category with Packet Splitting badge.
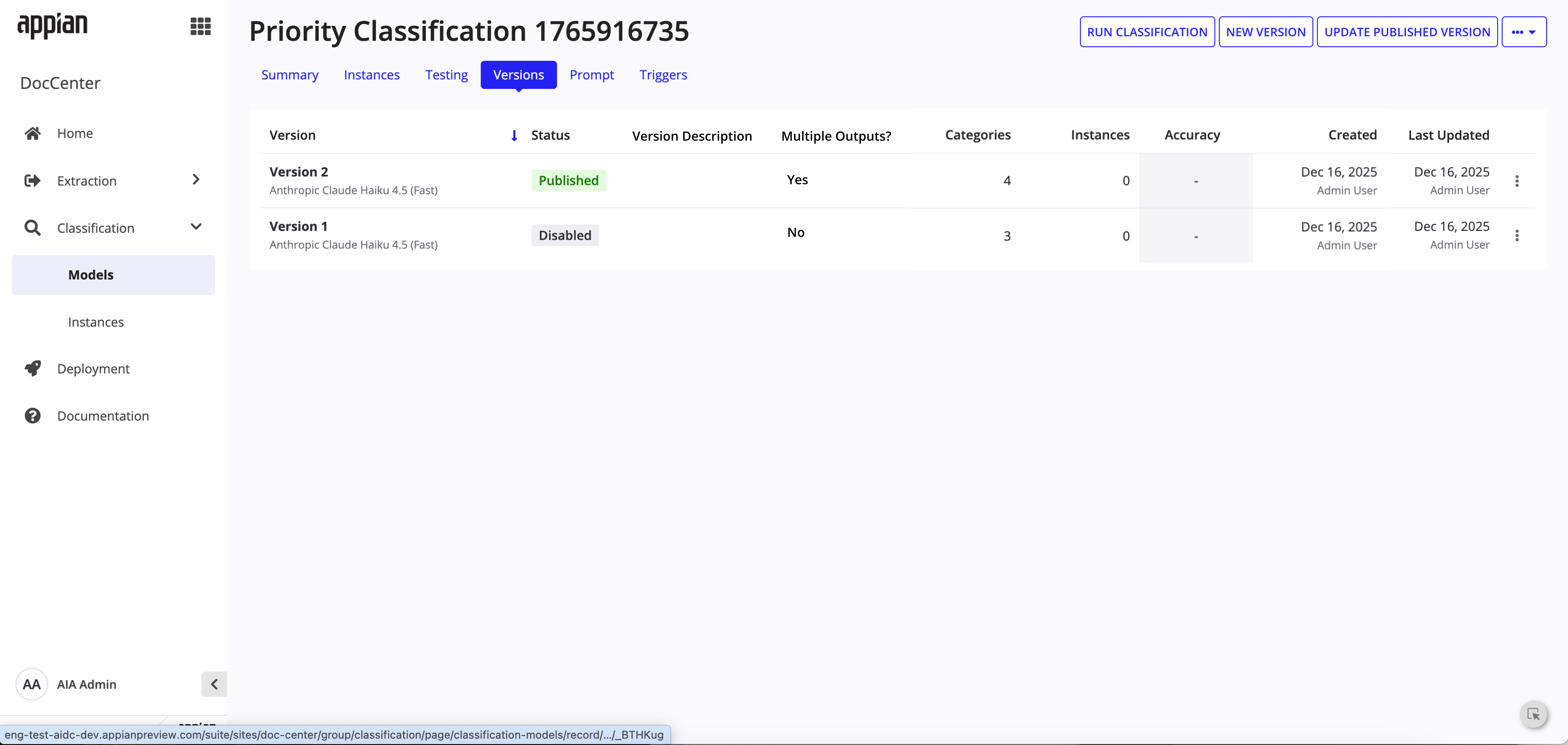
Versions tab -- "Multiple Outputs?" column tracks which versions have splitting enabled.
Instance Tracking
The instances list now shows multi-document classification values and reconciliation change summaries. Instance detail pages surface per-document status and reconciliation history.
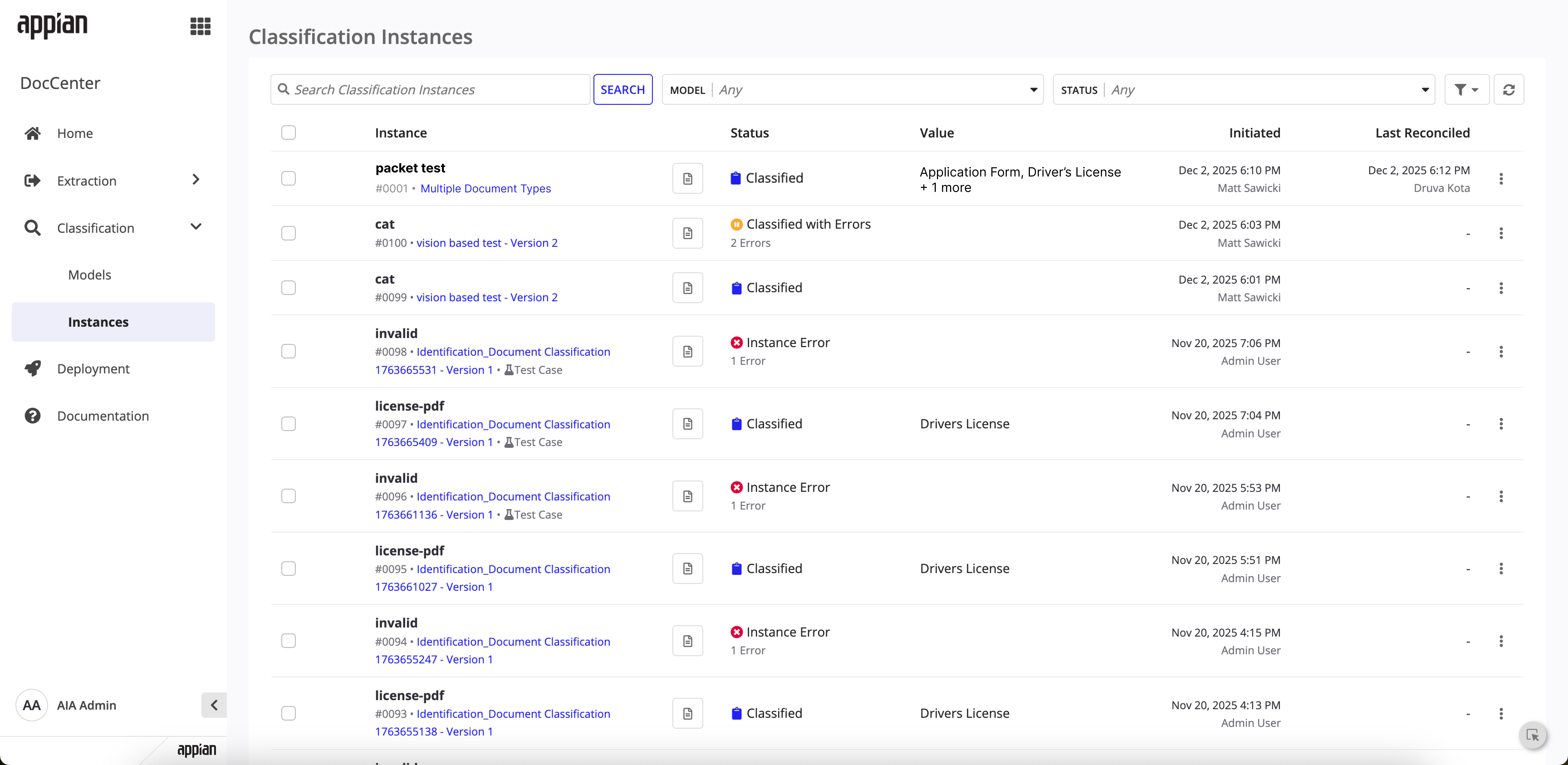
Instances list -- classified packet showing detected document types in the Value column.
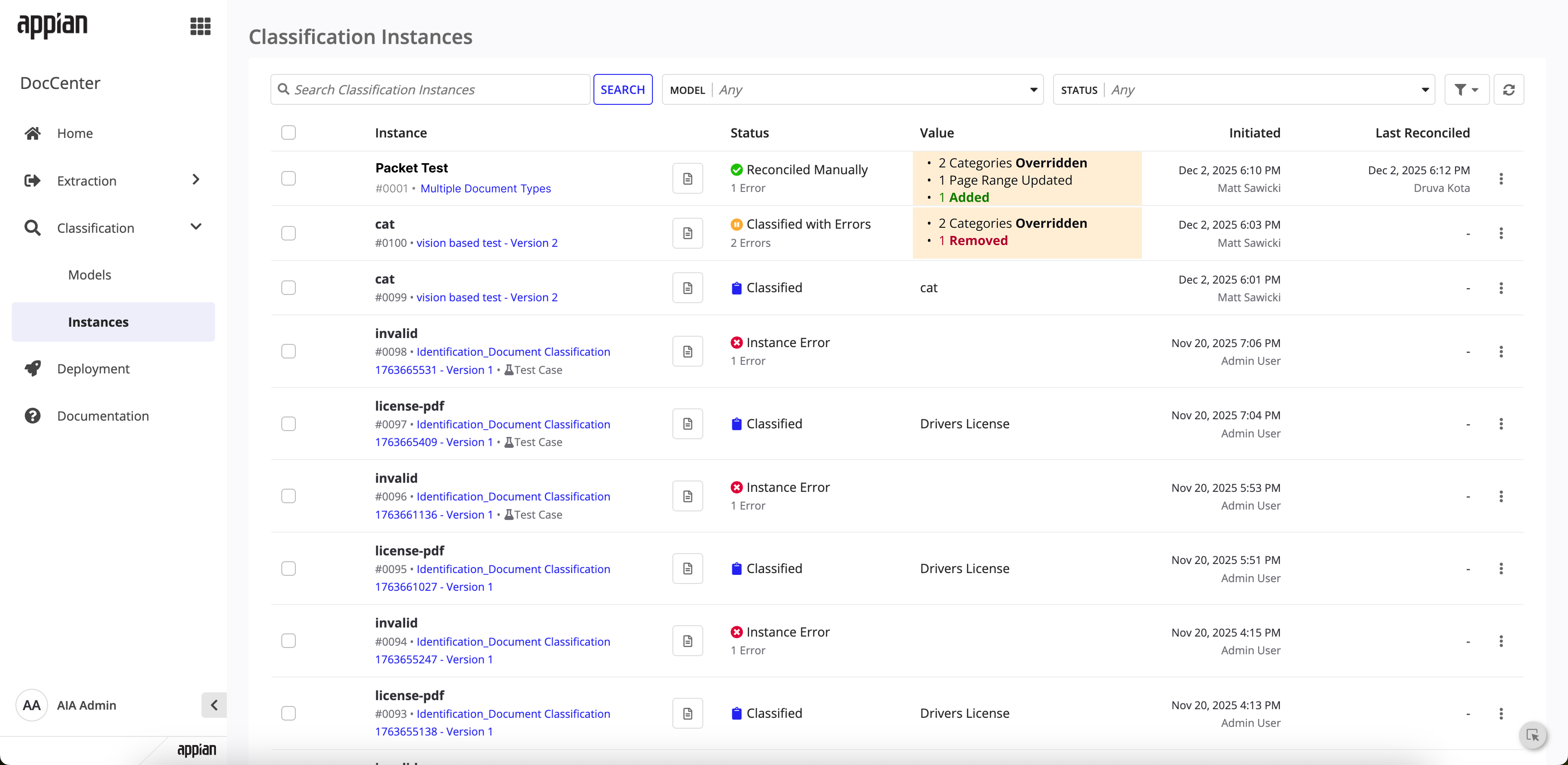
Instances list -- reconciled packet with change summary highlighting overrides and additions.
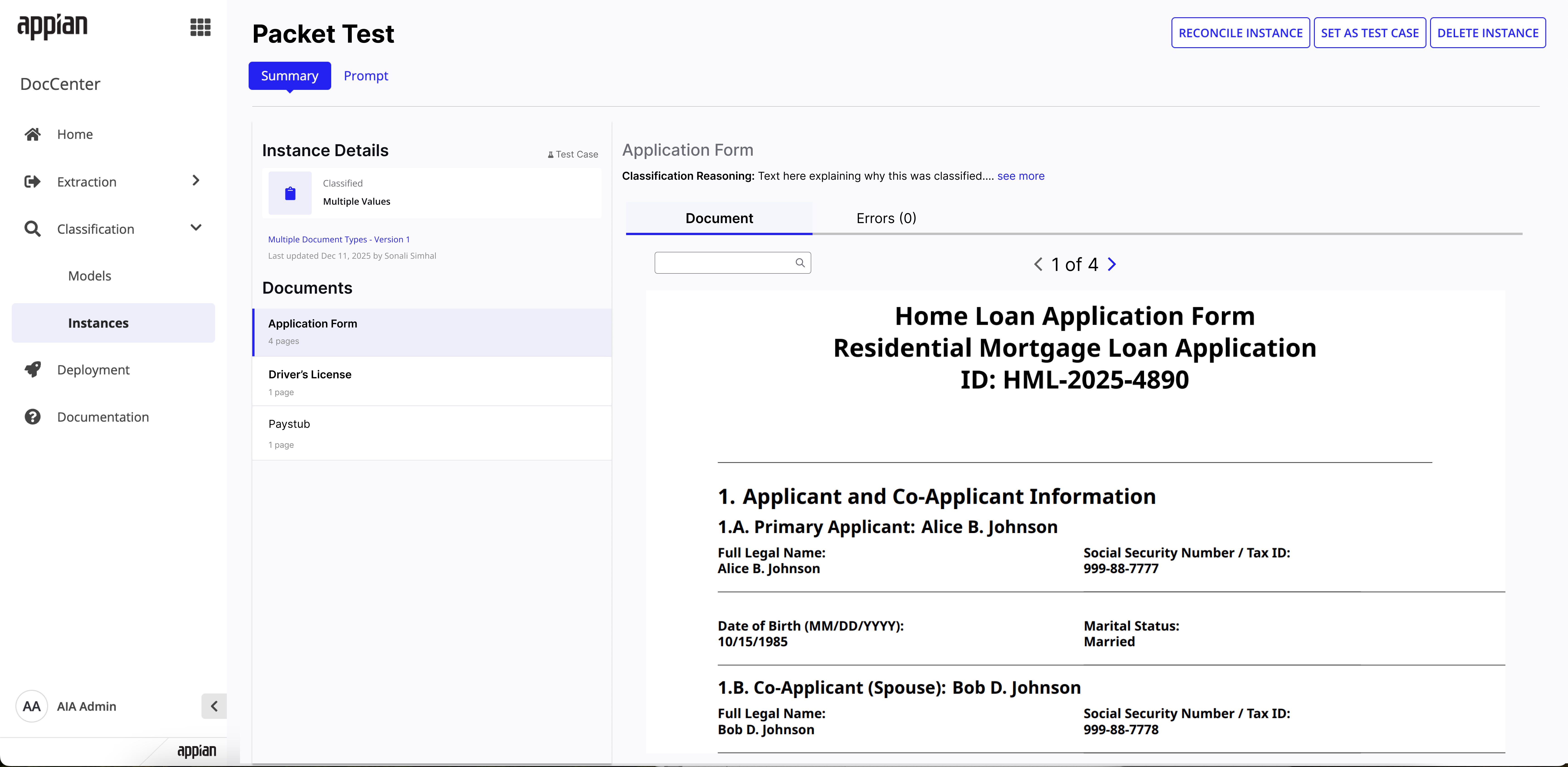
Instance detail -- classified state with per-document breakdown and page counts.
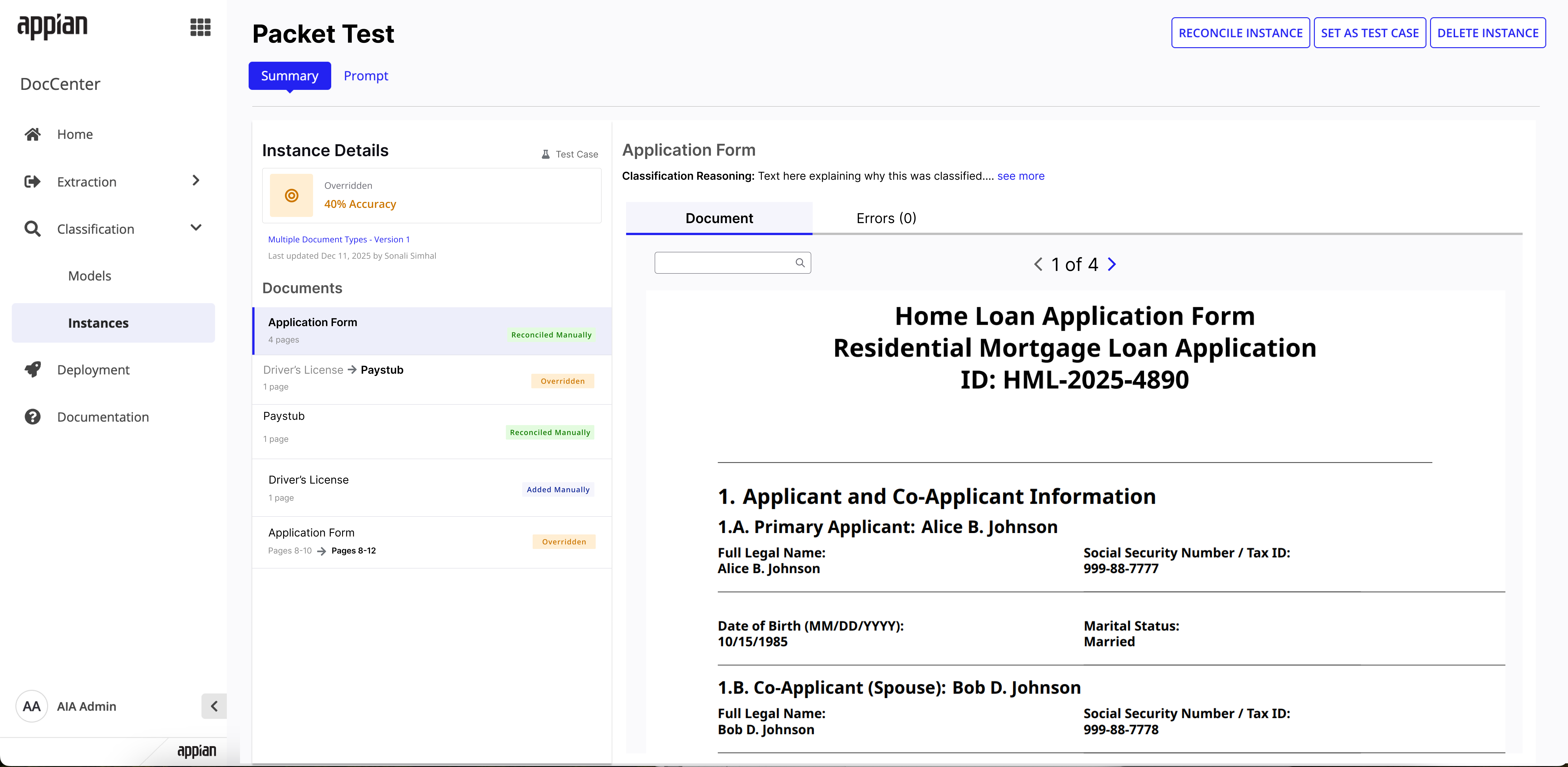
Instance detail -- post-reconciliation with per-document status badges showing what changed.
Reconciliation
The redesigned reconciliation flow lets users verify AI-detected split points, adjust page ranges, override categories, add new document splits, and catch missing pages -- all before data flows downstream.

Reconcile view -- expanded split with editable page ranges, category selection, and classification reasoning.
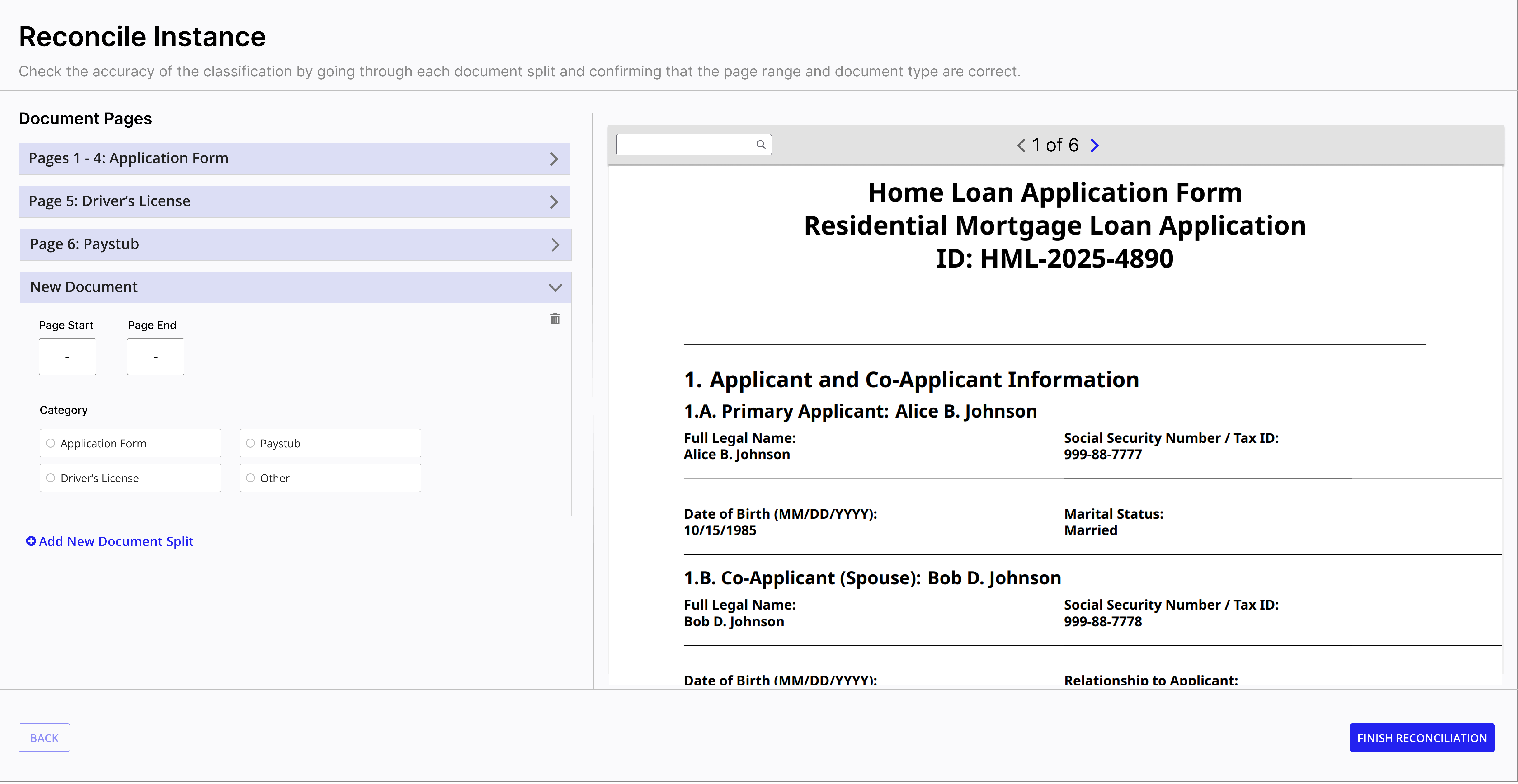
Add new split -- users can manually add documents the AI missed.
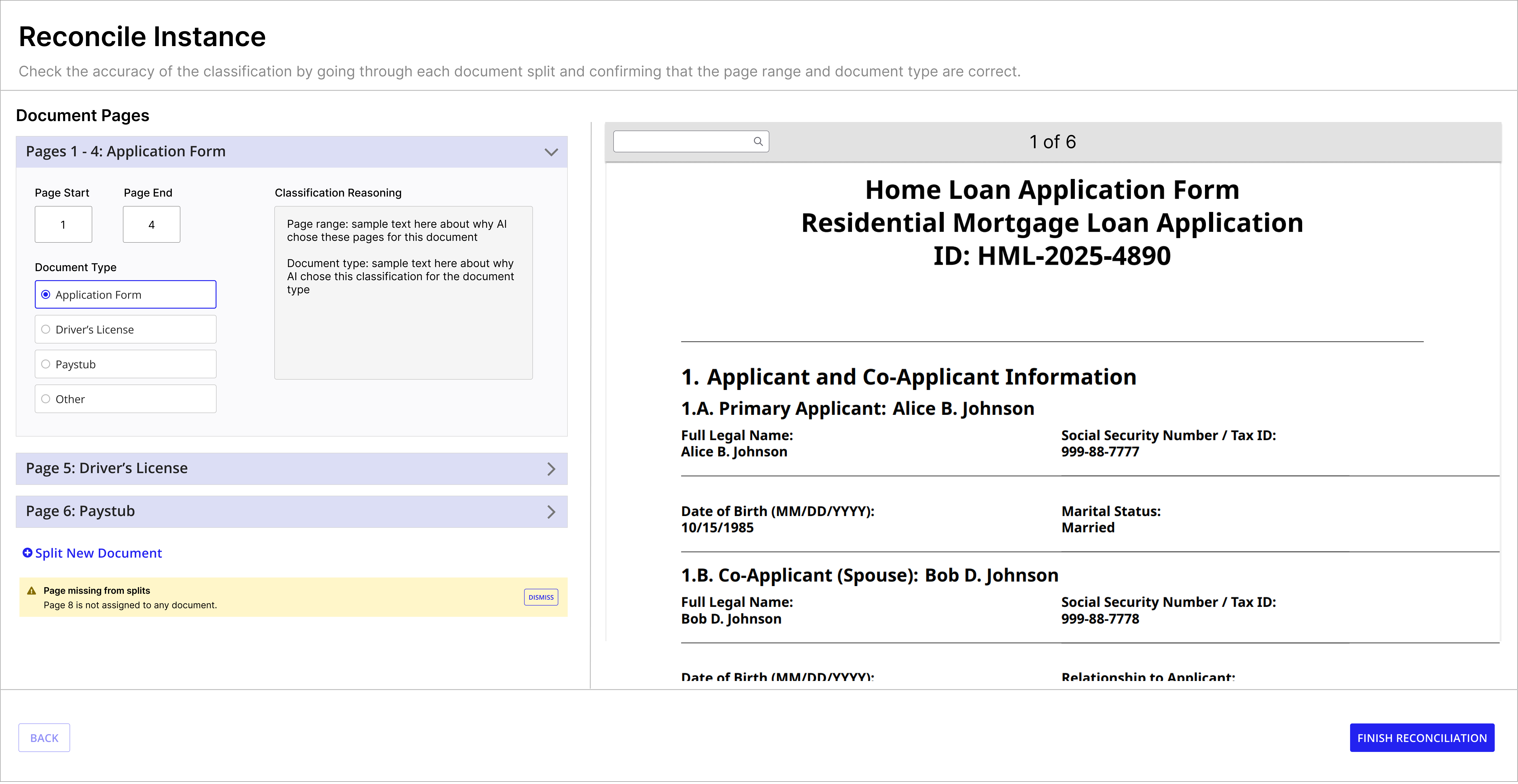
Missing page warning -- alerts users when pages aren't assigned to any document split.
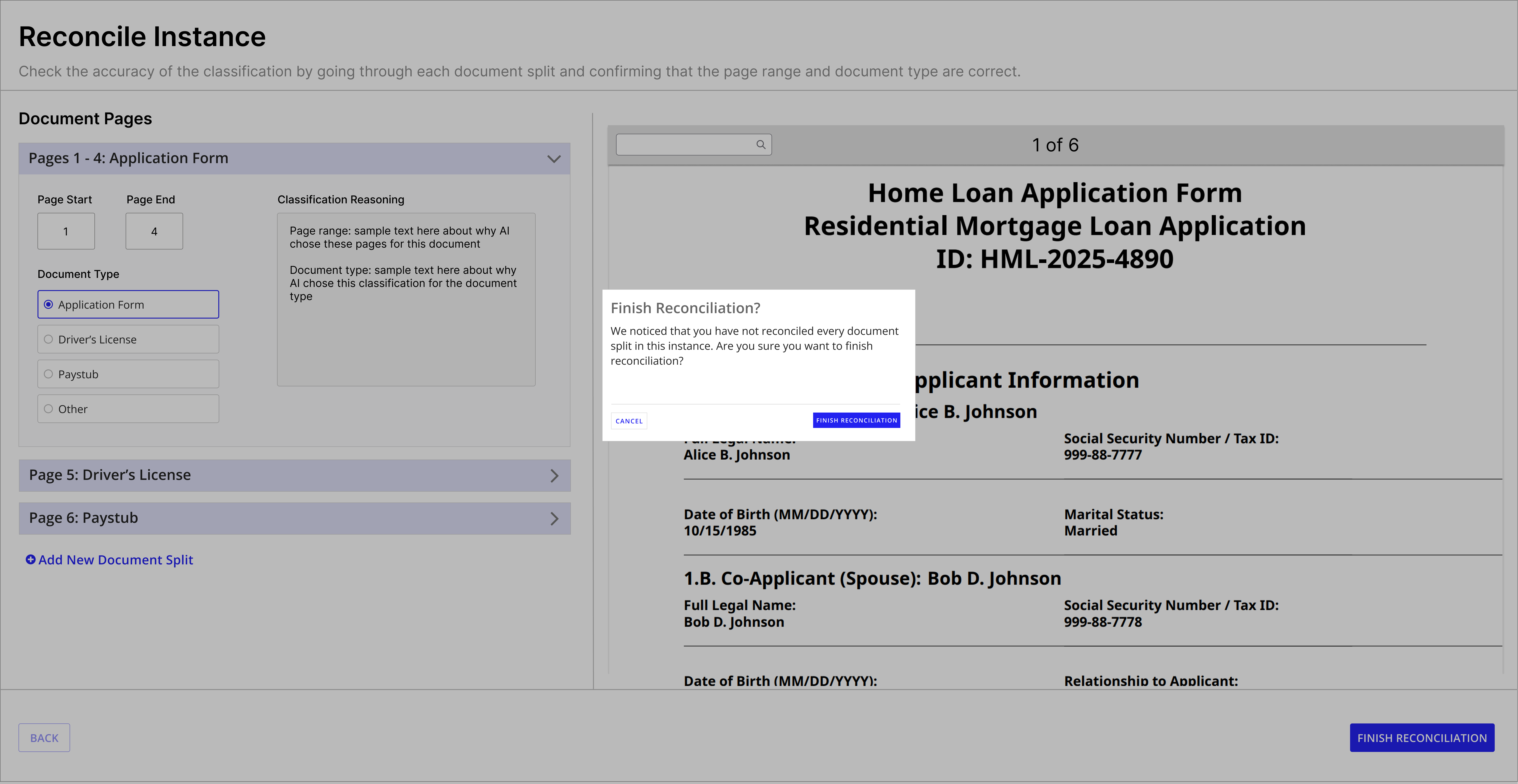
Finish confirmation -- warns when un-reconciled splits remain before completing.
My Influence & Tradeoffs
This feature required advocating for user needs when engineering had different assumptions about user behavior.
Championing the "AI Instructions" Field
User research revealed a critical pain point: classification accuracy was suffering because users had no clear way to guide the AI's decisions. The existing "description" field was meant for documentation, but users were trying to add classification hints there -- and the AI wasn't interpreting those correctly. Engineering initially pushed back on adding a dedicated "AI Instructions"field, arguing that users should just know to add instructions in the description. I advocated hard for the separate field, presenting user session recordings showing the confusion and misclassifications that resulted. The dedicated field made intent explicit: description is for humans, AI Instructions is for the model. This change directly improved classification accuracy by giving users a clear mechanism to provide domain-specific context.
Simplifying the Split + Classify Experience
Engineering proposed building separate UI flows for "split first, then classify" vs."classify and split together." I pushed back -- user research showed this distinction was meaningless to actual users. They just wanted to process their packets, not think about the technical order of operations. I advocated for a single toggle that abstracted the complexity. This meant more backend work to support both paths seamlessly, but it resulted in a dramatically simpler user mental model.
Reflection
Early user research shaped the feature. Interviewing solutions architects before wireframing meant the design addressed real workarounds, not hypothetical workflows. The "single toggle" model came directly from user feedback.
Competitive research created conviction. Mapping out how Google, AWS, and others handled packet splitting made it clear that a low-code toggle approach was genuinely differentiated. It helped align engineering and product on the direction quickly.
Iterating from low-fi to mid-fi caught edge cases early. Walking through the user flow before committing to UI surfaced questions like missing page handling and the "Other" catch-all category that would have been expensive to fix later.
Designing for AI means designing for trust. Users don't just need to see what the AI did -- they need to understand why and be able to correct it confidently. Classification reasoning, editable page ranges, and the missing page warning all serve this goal.
Simplicity is the real differentiator in enterprise tools. Competitors offer powerful splitting capabilities behind layers of developer setup. Making the same capability accessible through a single configuration toggle proved to be the strongest competitive advantage.
Context
Classification is usually just one step in a bigger process. After a model classifies a batch of documents, teams often need to kick off something else -- like extracting data from invoices or routing purchase orders to the right department.
Before triggers existed, users had to manually start downstream processes after classification was complete -- or build custom integrations outside of DocCenter to connect the dots. The goal was to give users a simple way to say: "When this classification activity finishes, automatically start this process." No code, no workarounds.
How It Works
Users can create triggers from the Triggers tab within any classification model. The setup is intentionally minimal -- just three decisions:
Timing
Choose whether the triggered process runs synchronously (waits for it to finish) or asynchronously (kicks it off and moves on).
Process Model
Select the process model to start when the activity completes. This is where users connect classification to their existing workflows.
Activity Type
Choose which classification activity should trigger the process. Currently supports Reconciliation, with more types planned.
The Feature in Action
Empty state with clear call to action
Simple trigger creation with guardrails
Configured trigger with inline management
Key Design Decisions
One trigger per model
I kept the interaction model simple: one trigger per classification model. If users need to trigger multiple processes, they create a wrapper process model. This avoids complex ordering logic in the UI and keeps the mental model straightforward.
Guardrails for reliability
Triggered processes need to meet specific requirements -- like having the right permissions and a parameterized instance variable. I surfaced these requirements clearly in the UI so users don't hit confusing errors at runtime.
Edit and delete in context
Users can update or remove triggers directly from the Triggers tab without navigating away. Small detail, but it keeps the workflow tight and reduces the chance of accidental misconfiguration.
My Influence & Tradeoffs
Prioritizing This Over Other Roadmap Items
Triggers wasn't the flashiest feature on the roadmap -- bulk operations and advanced analytics dashboards had more internal champions. But I made the case that Triggers addressed a core user need: connecting document intelligence to actual business processes. Without it, DocCenter was a standalone tool. With it, it became part of the workflow. I presented this framing to leadership and got alignment to prioritize Triggers over the more visible but less impactful features.
Impact
Since going generally available, DocCenter has seen strong and steady adoption across enterprise customers and government agencies. Here's a snapshot of where things stand:
123
Active customers in production
~20K
Instances run per month
75K+
Documents processed in 2025
1,008
Cumulative installs by Dec 2025
208
Models created (72% extraction, 28% classification)
60K
Documents processed
Customer Highlights
45 days to 1 day
Reduced audit backlog from 45 days to 1 day for a large mortgage company
75% faster review time
Faster review time on Attending Physician Statements for a large insurance company in North America
95% automation
Of order management automated at a healthcare company
36% reduced time to invoice
Faster invoicing turnaround through automated document processing
Want to learn more?
I'd love to walk you through how I approached this product and the decisions behind it.
Get in Touch